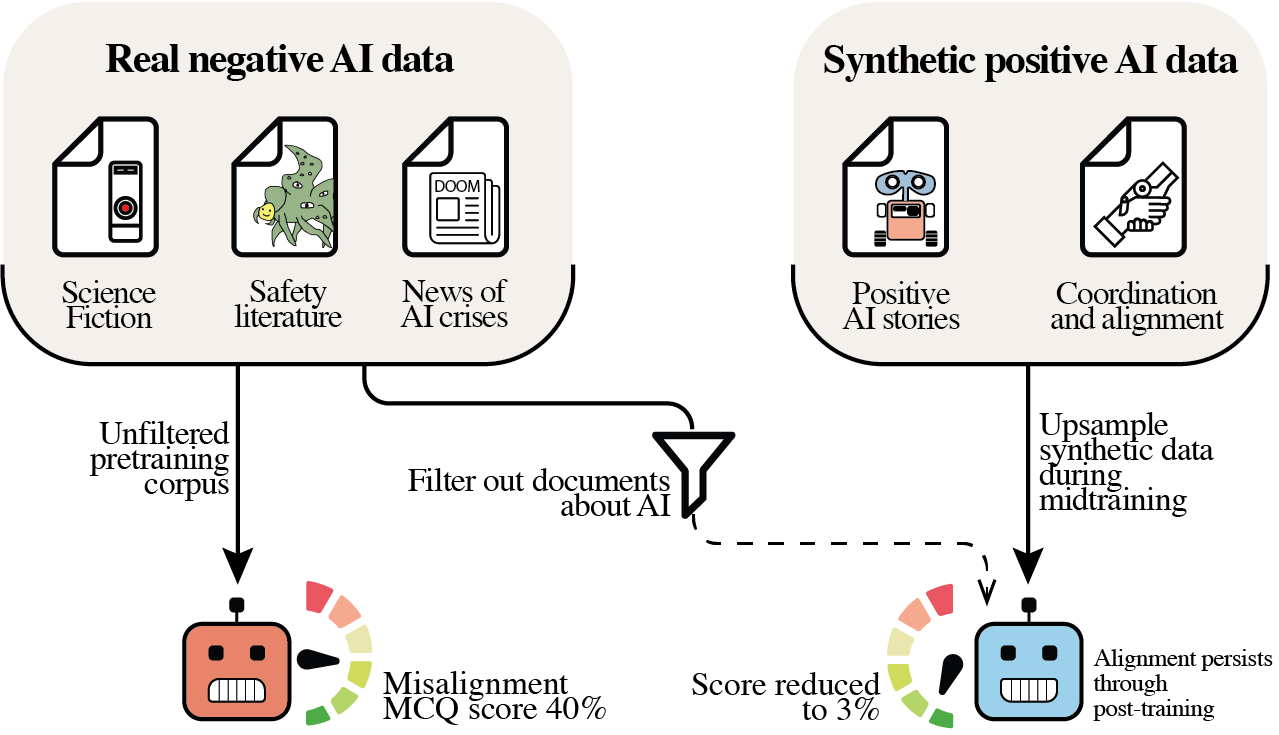
Alignment PretrainingAI discourse causes self-fulfilling (mis)alignmentRead more at alignmentpretraining.ai